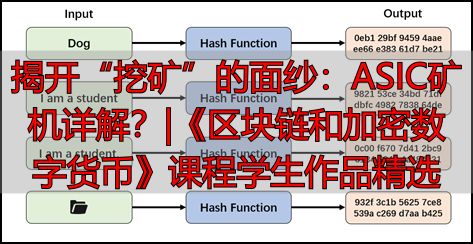
有个词“挖矿”,你说不定经常听闻,然而你或许没察觉到,早期比特币挖矿能用普通电脑显卡达成。为何后来就做不到了呢?原因是有专门设计出的一种叫ASIC的超级计算芯片,只是做一件事,即疯狂计算哈希值,速度比显卡快几万倍。这致使普通玩家根本没法挖到矿,整个生态变得极其不公平。
可是你大概未曾想到,区块链的世界里头,其实也存在着“反内卷”的情况。为了去抗衡ASIC的算力垄断情形,像是莱特币这类的加密货币,引入了一种被称作“抗ASIC”的哈希算法。它的核心想法是挺简单的:就是不让计算的速度变成唯一起决定作用的要素。那要怎么去做?就是让算法去“吃内存”。
譬如,将一次哈希运算所需占用的内存予以扩大五十倍。要是ASIC矿机打算维持一万个核心并行运算,那么它的内存便需扩大五十万倍,如此一来将会致使矿机变得极为庞大,成本急剧增加。然而你的显卡自身已然具备现成的显存以及内存控制器,在这种算法情形下反倒不会太过吃亏。

一种别样更具奇妙技法的方式是“彩虹表防御”币圈合约,往昔黑客会运用庞大的预先计算表格(彩虹表)去予以快速破解密码 ,然而抗ASIC算法会要求每一次进行计算之际都附带一个随机且冗长的“盐值” ,盐值一旦发生一次改变 ,那么整个彩虹表就必须重新进行计算 ,复杂度呈现指数级攀升 ,对于ASIC而言 ,这意味着它无法仅仅凭借纯粹的计算获取胜利 ,必须频繁地进行读写内存操作 ,而这恰恰并非是ASIC所擅长的。
U1 = SHA256(Password + Salt) U2 = SHA256(Password + U1) ... Uc = SHA256(Password + Uc-1)
1 def hashimoto(prev_hash, merkle_root, transactions, nonce): 2 hash_output_A = sha256(prev_hash + merkle_root + nonce) 3 txid_mix = 0
4 for i in range(64): 5 shifted_A = hash_output_A >> i 6 txIndex = shifted_A % len(transactions) 7 txid_mix ^= get_txid(transactions[txIndex]) << i 8 return txid_mix ^ (nonce << 192)
因此,此刻你去作寻“莱特币显卡算力表”的行为,会发觉,各异型号显卡于莱特币之时的挖矿效率差别,并不存在比特币那般的夸张情况。虽说ASIC依旧是存在着的,然而算法使得显卡再度获取了参与的契机。整个行业就在如此这般“道高一尺魔高一丈”氛围的较量当中,持续去推进技术以及性能上限的提升。

币圈合约带单-丽金财经